freeeのデータを継続的に扱うなら、CSVよりもAPIのほうが筋が良くなる場面があります。 APIなら、定期実行で常に最新データを取得でき、複数事業所もループで回せて、整形済みのJSONがそのまま返ってきます。
ただ、実際に作ろうとすると 「動かすまで」より「運用に乗せてから」のほうが手強い というのが実感です。 本記事では、freee APIで会計・経費・請求書データなどを取得する基本的な流れと、実務で引っかかりやすいポイントを、技術者向けに整理します。
前提: freee APIの仕様は更新されることがあるため、本記事は概念整理が中心です。実装時は必ず freeeのAPIリファレンス を確認してください。
freee APIでできること
freeeはアプリケーション開発者向けにOAuth2ベースのREST APIを提供しています。 代表的に取得できるデータは以下です。
- 仕訳・取引・試算表
- 請求書・見積書・発注書
- 経費精算・各種申請
- 取引先・勘定科目・部門・品目などのマスタ
- ファイルボックス内の証憑
- 人事労務freee側の従業員・給与情報(別アプリとしてのAPI)
CSVと違い、
- IDで関連オブジェクトを引ける
- 差分取得(更新日時での絞り込みなど)がしやすい
- 整形済みのJSONを直接処理できる
ため、 「分析できる状態」のデータをDWHに継続投入する という用途には、CSVより構造的に向いています。
関連記事: freeeでCSVエクスポートする方法と注意点 — CSV運用が向くケース/向かないケースを比較しています。
アプリの登録と権限設定
freee APIを使うには、まず freeeアプリストア / 開発者向け管理画面 で アプリを登録 する必要があります。 登録すると Client ID / Client Secret が発行され、OAuth2の認可フローやAPI呼び出しの起点になります。
パブリックアプリとプライベートアプリ
アプリ作成時に「アプリタイプ」を選びます。社内データを自分たちのDWHに連携するような用途では、基本的に プライベートアプリ で十分です。
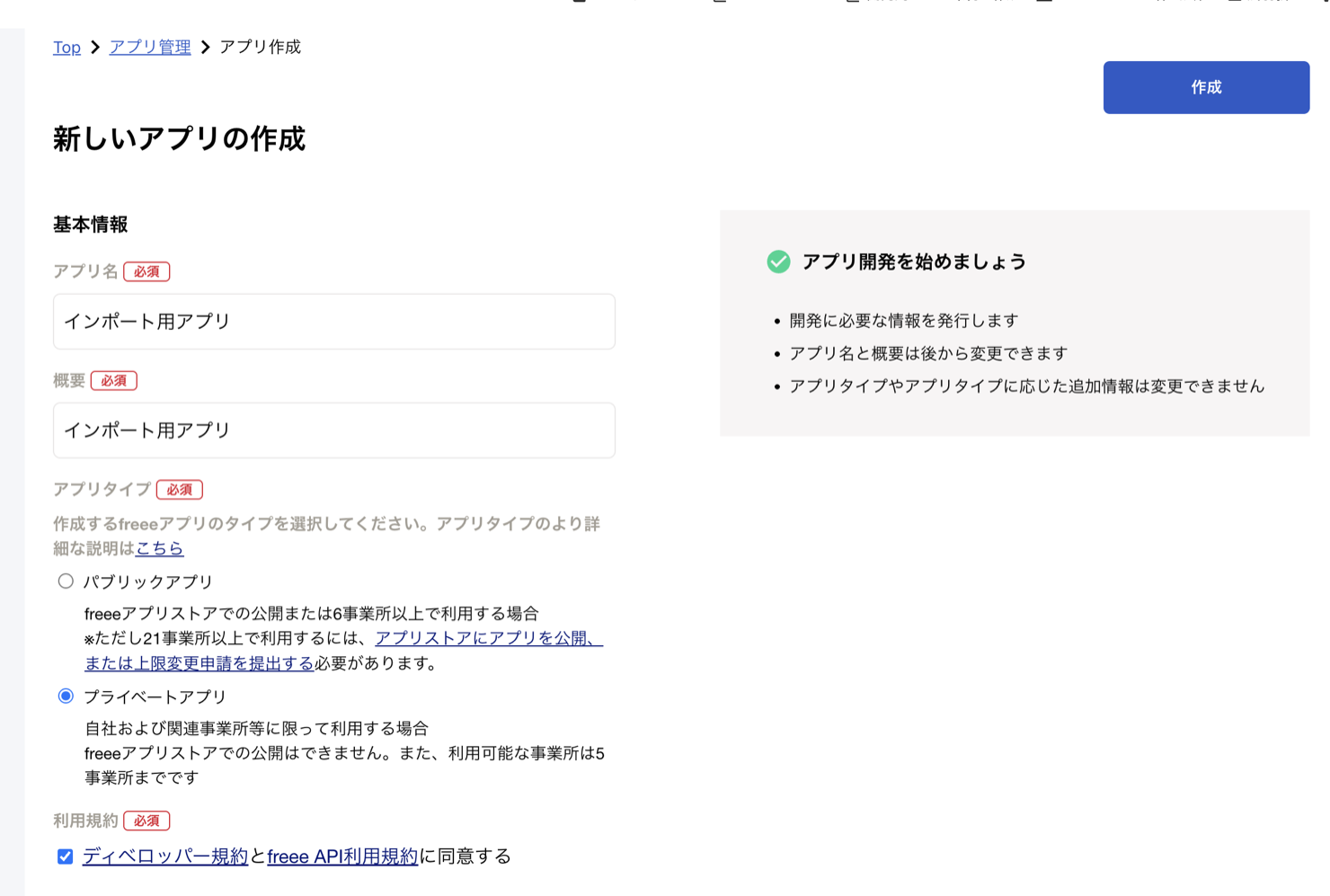
ざっくりした使い分けは次のとおりです。
- パブリックアプリ
- freeeアプリストアに公開する場合
- 6事業所以上で使う場合(自社利用でも事業所数が多いと必要)
- 不特定多数のユーザーに使ってもらうSaaSを作る場合
- プライベートアプリ
- 自社や関連会社の限られた事業所内で使う場合
- 公開はできない/最大5事業所までという制約あり
- 開発・検証の段階でも、まずはこちらで始めるのが一般的
社内分析基盤としてfreeeのデータをBigQueryに流したい、という用途であれば、プライベートアプリで作るのがいちばん素直です。
権限設定(スコープ)の考え方
アプリを作成したあと、「権限設定」タブで このアプリがアクセスできるデータ種別 を選びます。 データ種別ごとに「参照」「更新」のチェックボックスがあり、必要なものだけにチェックを入れる形式です。
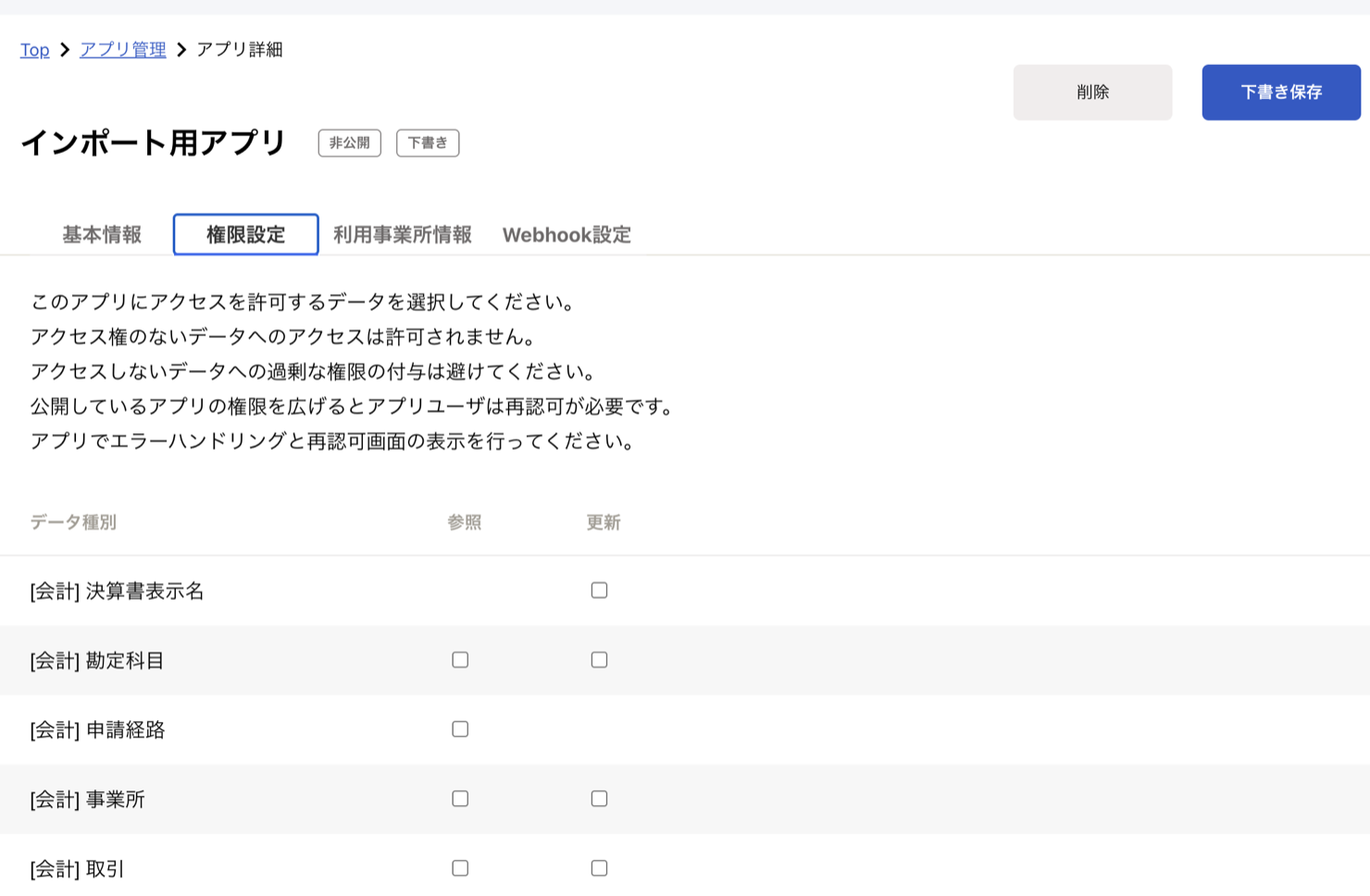
設計時に意識したいのは次のあたりです。
- 過剰な権限は付けない: 公式画面でも「アクセスしないデータへの過剰な権限の付与は避けてください」と明記されている。データ取得が目的なら、基本は 参照だけにチェック で済む
- 後から権限を広げると再認可が必要: 公開しているアプリで権限を広げると、ユーザー側に再認可をお願いする必要が出る。 エラーハンドリングと再認可フロー をあらかじめ用意しておくと運用が楽
- 会計/人事労務/販売 など、APIごとにスコープが分かれている: 一気に全部チェックするのではなく、「どのエンドポイントを叩く予定か」から逆算してチェックする
- Webhookも別タブで設定できる: 受動的にイベントを受けたい場合は権限設定とは別に Webhook 設定が必要
「とりあえず全部チェック」にしておくと、悪意ある攻撃を受けたときの被害範囲が広がります。最小権限で始めて、必要になったら追加する、という運用が安全です。
認可コードフローの詳細は公式リファレンスを参照
アプリ登録後の OAuth2 認可コードフロー(リダイレクトURI、認可エンドポイント、トークンエンドポイントの仕様など)は、freeeの公式ドキュメントが詳しいです。
実装ではこのドキュメントどおりに進めれば、ひとまず動かすところまでは到達できます。 ただ、 認証フローを動かすこと と 業務で安定運用すること には少し距離があります。次のセクションから、その「動いた後」の話に入っていきます。
freee APIでデータ取得する基本的な流れ
ざっくりと、典型的な実装はこんな順番になります。
- freeeにアプリ(多くの場合プライベートアプリ)を登録し、Client ID / Client Secret と必要なスコープを設定する
- ユーザーにOAuth2の認可フローでログインしてもらい、認可コードを受け取る
- 認可コードをアクセストークン/リフレッシュトークンに交換する
- アクセストークンを
Authorization: Bearer <token>ヘッダに付けてAPIを呼ぶ - 必要に応じてリフレッシュトークンでアクセストークンを更新する
- ページネーションをループしながら全件取得する
- 取得したデータをDWH(BigQueryなど)に格納する
ここまでは「APIを触ったことがある人なら一度は通る」流れです。 問題は、これを業務で動かし続けるときに出てきます。
認証とトークン管理
freee APIで最初にハマりやすいのが認証周りです。
OAuth2の認可フロー
freeeのトークンは「ユーザーに紐づく」ため、
- 取得対象の事業所にアクセス権を持つユーザーのトークンが必要
- 退職や権限変更でユーザーが事業所から外れると、トークンが使えなくなる
- 法人の代表的な「サービスアカウント的なユーザー」は基本存在しないので、運用ルールを決めておく必要がある
という前提で設計する必要があります。
アクセストークンとリフレッシュトークン
実装上で気をつけたいのは次の点です。
- アクセストークンには有効期限がある(短め)
- リフレッシュトークンは原則 1回使うと新しいリフレッシュトークンに置き換わる(ローテーション)
- 古いリフレッシュトークンを使い回すとエラーになる
- 並列にトークン更新をかけると、片方の更新で他方が無効化されることがある
特に最後の点は、定期実行を並列化したときに静かに事故ります。 トークン更新は排他制御してシリアライズする、というのは経験的に必須に近いです。
トークンの保管場所
DBに平文で置くのは避けたほうが良いです。
- KMSで暗号化する
- Secrets Manager などに置く
- 取得元がわかる監査ログを残す
このあたりは、freee以外のSaaS連携にもそのまま当てはまる話です。
データ取得時に考えること
エンドポイント自体はわかりやすく作られていますが、実装してみると次のような点で判断が必要になります。
全件取得 vs 差分取得
- 初回は全件取得が必要
- 2回目以降は 更新日時 で差分取得するのが現実的
- ただし「論理削除されたレコード」をどう扱うかは別途設計が必要
- APIで「削除フラグ付きで返ってくる」ものと「単純に消えるだけ」のものがある
- DWH側で「翻訳元データ」とのスナップショット差分を取りたいケースもある
スキーマの揺れ
- 一部のフィールドは null / 空配列 / 未指定 が混在する
- enum的に扱える項目でも、新しい値が後から増えることがある
- 列追加は静かに起きる(ドキュメント更新とAPIレスポンス更新のタイミングがずれることもある)
DWHにそのまま入れるなら、スキーマ追従の仕組み(カラム追加検知や型ガードなど)を持っておくと安全です。
タイムゾーン
freee側のタイムスタンプはJST前提のフィールドが多めです。 BigQueryなどUTC前提の世界に入れる際は、保存時にUTCへ寄せるのか、表示時に変換するのか、最初に決めておかないとあとで集計がぶれます。
ページネーションとレート制限
ページネーション
多くのエンドポイントは limit と offset(あるいはカーソル)方式で結果を分割返却します。
実装では次の点に注意が必要です。
- limitの上限値を超えてリクエストすると、暗黙に丸められることがある
- 取得中にデータが追加・更新されると 同一レコードが重複 したり 抜け落ち たりする
- そのため、取得中はソートキー(IDや更新日時)を固定して、最後まで一貫させる
擬似コードで書くとこんなイメージです。
# 擬似コード: ページネーションの一般形
def fetch_all(endpoint, params):
offset = 0
limit = 100
results = []
while True:
page = api_get(endpoint, {**params, "limit": limit, "offset": offset})
results.extend(page)
if len(page) < limit:
break
offset += limit
return results
レート制限
- freeeにはAPI呼び出しのレート上限がある
- 上限超過時は 429 系のエラーが返ってくる
- 復旧待ちを単純な固定スリープで書くと、混雑時間帯に詰まる
実務では次のような実装になりがちです。
- 指数バックオフ + ジッター付きリトライ
- 並列度を抑える(無闇に同時リクエストしない)
- 1回のジョブで取り切れないときは、ジョブ自体をチャンクに分けて実行
「動いた/動かない」ではなく 「混雑時間帯でも壊れない」 に到達するまでが、地味に時間を食います。
複数事業所を扱う場合の注意点
複数事業所のデータをまとめて分析したい、というのは典型的なユースケースです。 APIで作る際に注意したいのは次の点です。
- アクセストークンには「対象の事業所一覧」のスコープがある(ユーザーが所属する事業所群)
- どのユーザーのトークンを使うかで、取れる事業所が変わる
company_idをリクエストごとに正しく指定する必要がある- 事業所ごとにスキーマが微妙に違うことがある(独自勘定科目、税区分の使い方など)
- DWH側では
company_idをパーティションキーや必須カラムにしておくと後段の集計が楽
「最初は1事業所で書いて、あとから複数化したらそこら中を直すことになった」というのは、よくある話です。
最初から company_id を引数化しておく設計にしておくと、後で泣きません。
API自作が向いているケース / 向いていないケース
| ケース | API自作 |
|---|---|
| 1事業所・特定エンドポイントだけ使う | ◎ シンプルに書ける |
| 既存の社内システムと密に連携したい | ◎ 自由度が高い |
| 独自の業務ロジックをAPI取得時に挟みたい | ◎ コードで好きにできる |
| 全エンドポイント・複数事業所を継続運用 | △ 運用負荷が読みにくい |
| 「分析基盤としてDWHに継続投入」 | △ スキーマ追従と認証運用がコスト |
| 専任エンジニアを当て続けられない | × 属人化しやすい |
API自作のいちばんのリスクは、「動いた直後の理解度がピーク」 という点です。 半年後にfreee側のスキーマが変わったときに、原作者がもう触れない、というのはよく起きます。
syncflowで肩代わりしていること
最後に少しだけ自社プロダクトの話です。
Syncflow は、freeeのデータをBigQueryに自動連携するサービスです。 APIを自前で実装する代わりに、
- OAuth認証とトークン更新(ローテーション・排他制御を含む)
- 仕訳・取引・請求書・経費・各種申請・ファイルボックス・マスタ・試算表の取得
- ページネーション・レート制限・リトライ
- 複数事業所のループ処理と
company_id管理 - BigQueryスキーマの追従とパーティション設計
- スケジュール実行と監視
といった部分を肩代わりしています。
「freee APIで自分でやる選択肢」と「ツールに任せる選択肢」を比較したいときは、こちらの記事も参考になります。
関連記事: freee CSV 自動化の方法【手動・API・ツールを比較】 — 手動・API・ツールの3つを並べて比較しています。
まとめ
freee APIを使うと、CSVでは難しい
- 差分取得
- 関連オブジェクト経由の取得
- 複数事業所の自動ループ
- DWHへの継続投入
が現実的になります。 一方で、認証・トークン管理・ページネーション・レート制限・スキーマ追従・複数事業所対応など、 「作る」より「運用する」ほうがコスト という性格があります。
判断軸はシンプルで、
- ロジックを自分たちで持ちたい / 個別要件が強い → API自作が向く
- データを「分析できる状態」で保ち続けたいだけ → ツールに任せたほうが速い
くらいの整理になると思います。 どちらが正解というよりは、 「自分たちで持つコストを引き受ける覚悟があるか」 で決まる話です。
freee APIの実装・運用を自前で持ちたくない方へ
Syncflowなら、freeeのデータをBigQueryへ自動連携できます。
OAuth・トークン更新・ページネーション・複数事業所対応まで、運用ごと肩代わりします。